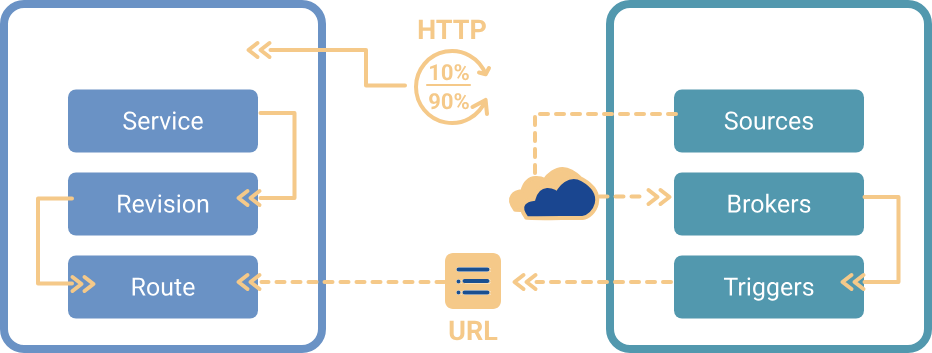
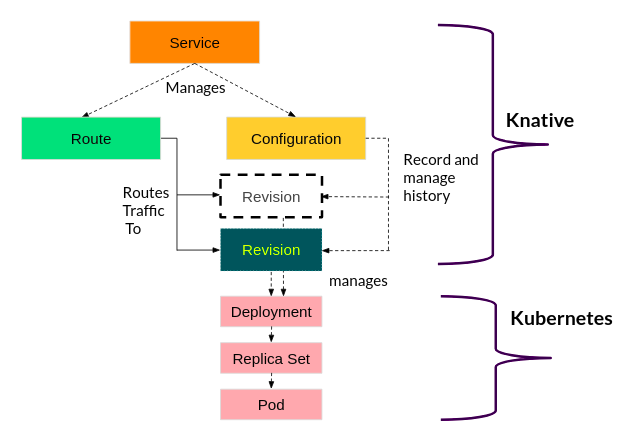
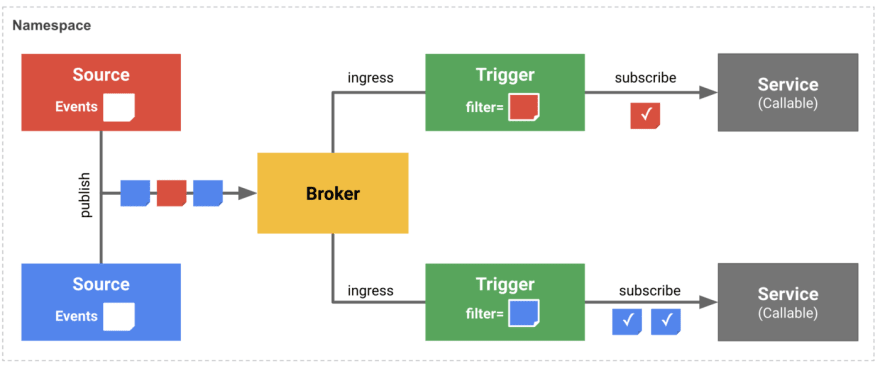
If you missed the first installment of our Knative series, you can catch up by diving into our previous blog post: Dive into Knative—Explore Serverless with Kubernetes
Overview
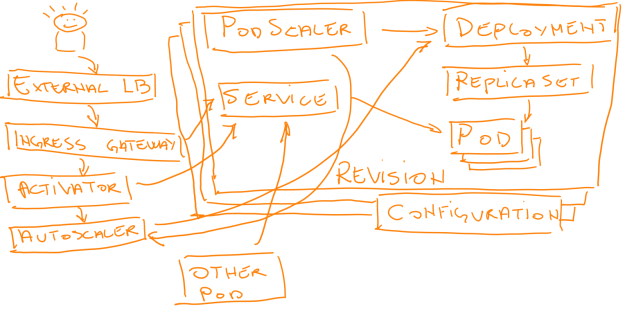
The key aspects and benefits of Knative Serving:
- Serverless Platform: Knative Serving is a serverless platform built on top of Kubernetes.
- Deployment Simplification: It simplifies the deployment of containerized applications on Kubernetes.
- Auto-scaling: Automatically scales applications based on demand, ensuring optimal resource utilization.
- Traffic Management: Provides features for managing traffic routing, allowing seamless updates and rollbacks.
- Focus on Development: Abstracts away infrastructure management complexities, enabling developers to focus on writing and deploying code.
- Cloud-Native Applications: Facilitates the development of modern, scalable, and resilient cloud-native applications.
For an introductory exploration of Knative Serving, delve into our dedicated Knative Serving section.
Knative Serving Architecture
Architecture Diagram
Knative Serving consists of several components forming the backbone of the Serverless Platform. This blog explains the high-level architecture of Knative Serving.
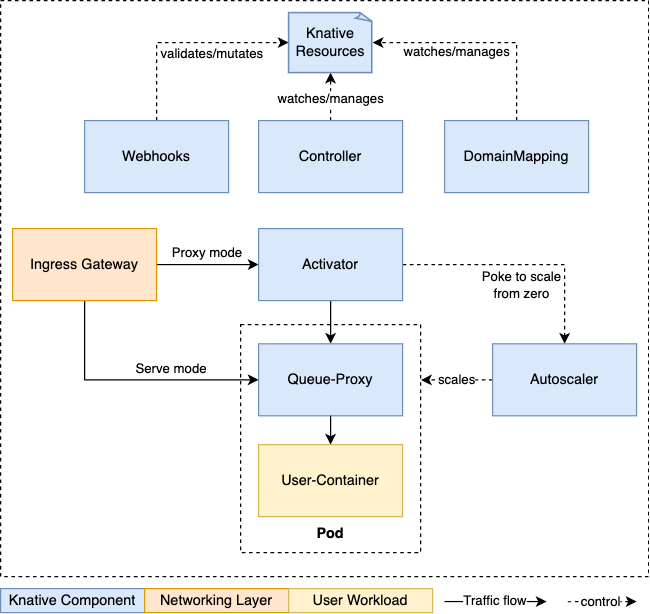
Components
- Activator: The activator is part of the [data-plane]. It is responsible to queue incoming requests (if a Knative Service is scaled-to-zero). It communicates with the autoscaler to bring scaled-to-zero Services back up and forward the queued requests. Activator can also act as a request buffer to handle traffic bursts.
- Autoscaler: The autoscaler is responsible to scale the Knative Services based on configuration, metrics and incoming requests.
- Controller: The controller manages the state of Knative resources within the cluster. It watches several objects, manages the lifecycle of dependent resources, and updates the resource state.
- Queue-Proxy: The Queue-Proxy is a sidecar container in the Knative Service's Pod. It is responsible to collect metrics and enforcing the desired concurrency when forwarding requests to the user's container. It can also act as a queue if necessary, similar to the Activator.
- Webhooks: Knative Serving has several webhooks responsible to validate and mutate Knative Resources.
HTTP Request Flows
This explains the behavior and flow of HTTP requests to an application which is running on Knative Serving.
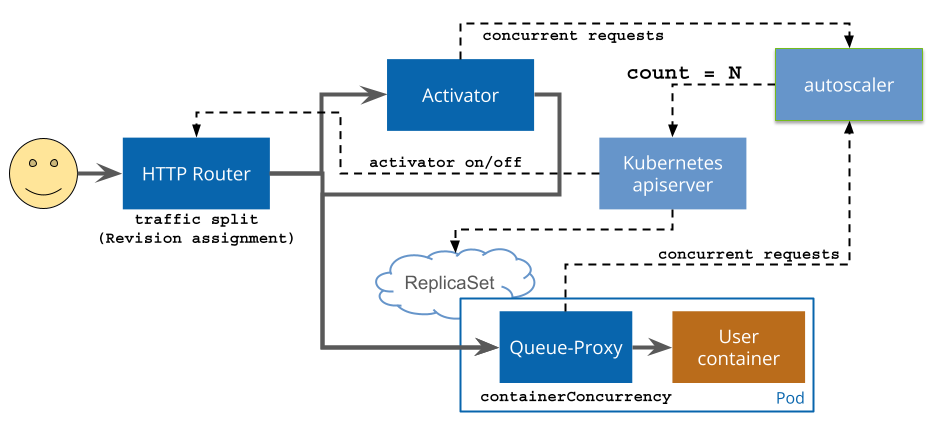
- Initial Request: When a user sends an HTTP request to your Knative service, it first hits the ingress gateway.
- Routing Decision: The ingress gateway examines the request to determine which Knative service should handle it based on the requested domain name.
- Service Activation: Knative Serving keeps your service deployed at all times. When a request arrives and no instances are running, it promptly activates a new instance by spinning up a pod.
- Scaling Decision: Knative Serving checks the current load and decides how many instances of the service need to be running to handle incoming requests efficiently.
- Activator Interaction: For the first-time request, it goes to the activator. The activator asks the auto scaler to scale up one pod to serve the initial request, ensuring rapid response and availability.
- Request Handling: The request is then forwarded to one of the instances of your service, where your application code processes it.
- Containerized Environment: Within each pod, there are two containers:
- User Container: This container hosts your application code, serving user requests.
- Queue Container: This container monitors metrics and observes concurrency levels.
- Auto-scaling Based on Concurrency: When the concurrency exceeds the default level, the autoscaler spins up new pods to handle the increased concurrent requests, ensuring optimal performance.
- Response: After processing the request, your service generates a response, which is sent back through the same flow to the user who made the initial request.
- Scaling Down: If there is no more traffic or if the traffic decreases significantly, Knative Serving may scale down the number of running instances to save resources.
Revisions
- Revisions are Knative Serving resources representing snapshots of application code and configuration.
- They are created automatically in response to updates in a Configuration spec.
- Revisions cannot be directly created or updated; they are managed through Configuration changes.
- Deletion of Revisions can be forced to handle resource leaks or remove problematic Revisions.
- Revisions are generally immutable, but may reference mutable Kubernetes resources like ConfigMaps and Secrets.
- Changes in Revision defaults can lead to syntactic mutations in Revisions, affecting configuration without altering their core behavior.
Autoscaling

Kubernetes Autoscaling Options
Knative Serving provides automatic scaling, or autoscaling, for applications to match incoming demand. This is provided by default, by using the Knative Pod Autoscaler (KPA).
For example, if an application is receiving no traffic and scale to zero is enabled, Knative Serving scales the application down to zero replicas. If scaling to zero is disabled, the application is scaled down to the minimum number of replicas specified for applications on the cluster. Replicas are scaled up to meet demand if traffic to the application increases.
Supported Autoscaler types
Knative Serving supports the implementation of Knative Pod Autoscaler (KPA) and Kubernetes' Horizontal Pod Autoscaler (HPA).
- Knative Pod Autoscaler (KPA)
- Part of the Knative Serving core and enabled by default once Knative Serving is installed.
- Supports scale to zero functionality.
- Does not support CPU-based autoscaling.
- Horizontal Pod Autoscaler (HPA)
- Not part of the Knative Serving core, and you must install Knative Serving first.
- Does not support scale to zero functionality.
- Supports CPU-based autoscaling.
Knative Serving Autoscaling System
APIs
- PodAutoscaler (PA):
- API:
podautoscalers.autoscaling.internal.knative.dev - It's an abstraction that encompasses all possible PodAutoscalers, with the default implementation being the Knative Pod Autoscaler (KPA).
- The PodAutoscaler manages the
scaling target, themetricused for scaling, and otherrelevant inputsfor the autoscaling decision-making process.- Scaling Target: The PodAutoscaler determines what resource it should scale. This could be the number of pods, CPU utilization, memory consumption, or any other metric that indicates the workload's demand.
- Metric for Scaling: It specifies which metric or metrics should be used to make scaling decisions. For example, it might use CPU utilization to decide when to add or remove pods based on workload demand.
- Other Inputs: The PodAutoscaler considers additional factors beyond just the scaling metric. These could include constraints, policies, or thresholds that influence scaling decisions. For instance, it might have rules to prevent scaling beyond a certain limit or to ensure a minimum number of pods are always running.
- PodAutoscalers are automatically created from Revisions by default.
- API:
- Metric:
- API:
metrics.autoscaling.internal.knative.dev - This API controls the collector of the autoscaler, determining which service to scrape data from, how to aggregate it, and other related aspects.
- Collector Control: The API controls the collector component of the autoscaler. The collector is responsible for gathering data related to the performance and behavior of the services being monitored for autoscaling.
- Data Scraping: It determines which service or services the autoscaler should scrape data from. This involves collecting relevant metrics such as CPU utilization, request latency, or throughput from the specified services.
- Aggregation: The API defines how the collected data should be aggregated. This could involve calculating averages, sums, or other statistical measures over a specific time window to provide a meaningful representation of the service's performance.
- Other Related Aspects: Beyond data collection and aggregation, the API likely handles other aspects such as data retention policies, thresholds for triggering scaling actions, and configurations for interacting with the autoscaler's decision-making process.
- Metrics are automatically generated from PodAutoscalers by default.
- API:
- ServerlessServices (SKS):
- API:
serverlessservices.networking.internal.knative.dev - It's an abstraction layer built on top of Kubernetes Services, managing the data flow and the switch between using the activator as a buffer or routing directly to application instances.
- SKS creates two Kubernetes services for each revision: a public service and a private service.
- The private service points to the application instances, while the public service endpoints are managed directly by the SKS reconciler.
- SKS operates in two modes: Serve and Proxy.
- In Serve mode, traffic flows directly to the revision's pods.
- In Proxy mode, traffic is directed to activators.
- ServerlessServices are created from PodAutoscalers.
- API:
Scaling up and down (steady state)
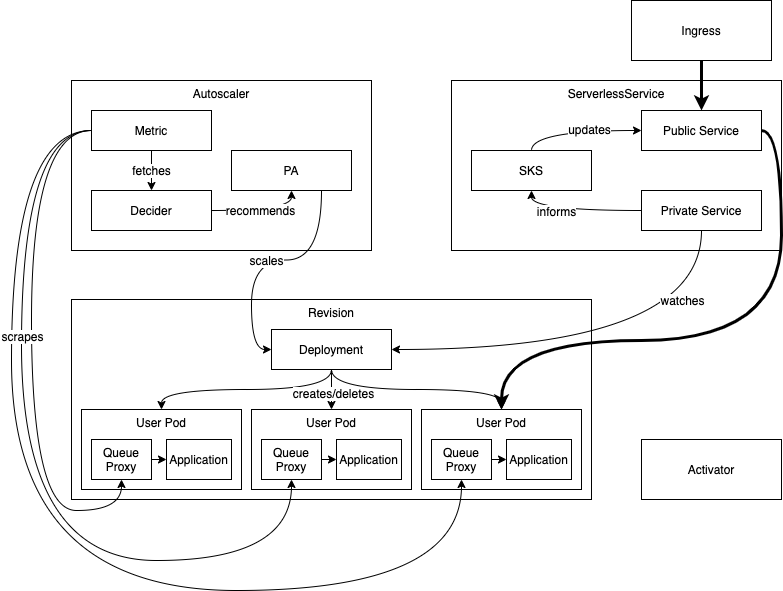
- Steady State Operation:
- The autoscaler operates continuously at a steady state.
- It regularly scrapes data from the currently active revision pods to monitor their performance.
- Dynamic Adjustment:
- As incoming requests flow into the system, the scraped values of performance metrics change accordingly.
- Based on these changing metrics, the autoscaler dynamically adjusts the scale of the revision.
- SKS Functionality:
- The ServerlessServices (SKS) component keeps track of changes to the deployment's size.
- It achieves this by monitoring the private service associated with the deployment.
- Public Service Update:
- SKS updates the public service based on the changes detected in the deployment's size.
- This ensures that the public service endpoints accurately reflect the available instances of the revision.
Scaling to zero
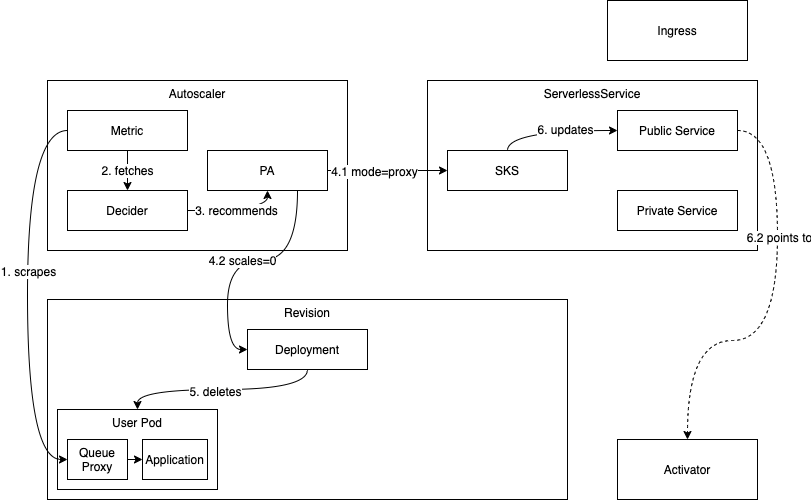
- Scaling to Zero Process (1):
- A revision scales down to zero when there are no more requests in the system.
- All data collected by the autoscaler from revision pods and the activator reports zero concurrency, indicating no active requests.
- Activator Preparation:
- Before removing the last pod of the revision, the system ensures that the activator is in the path and reachable.
- Proxy Mode Activation (4.1):
- The autoscaler, which initiated the decision to scale to zero, directs the SKS to switch to Proxy mode.
- In Proxy mode, all incoming traffic is routed to the activators.
- Public Service Probing:
- The SKS's public service is probed continuously to ensure it returns responses from the activator.
- Once the public service reliably returns responses from the activator and a configurable grace period (set via scale-to-zero-grace-period) has elapsed,
- Final Scaling Down (5):
- The last pod of the revision is removed, marking the successful scaling down of the revision to zero instances.
Scaling from zero
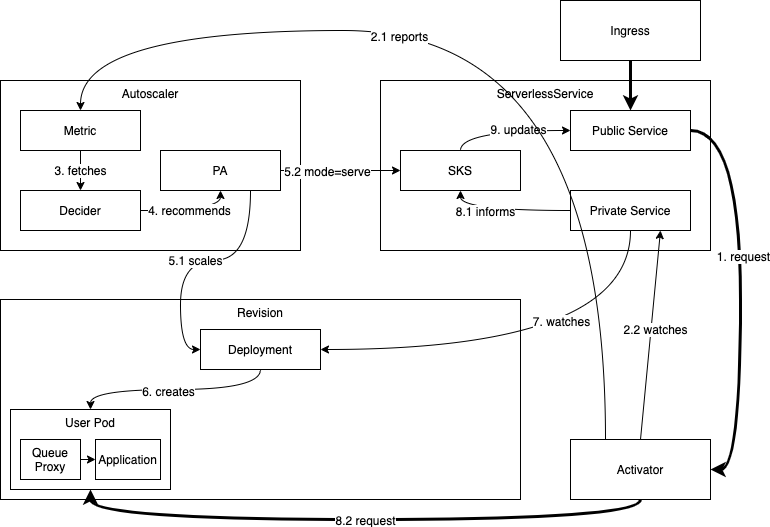
- Scaling Up Process:
- If a revision is scaled to zero and a request arrives for it, the system needs to scale it up.
- As the SKS is in Proxy mode, the request reaches the activator.
- Request Handling:
- The activator counts the incoming request and reports its appearance to the autoscaler (2.1).
- It then buffers the request and monitors the SKS's private service for endpoints to appear (2.2).
- Autoscaling Cycle (3):
- The autoscaler receives the metric from the activator and initiates an autoscaling cycle.
- This process determines the desired number of pods based on the incoming request.
- Scaling Decision (4):
- The autoscaling process concludes that at least one pod is needed to handle the incoming request.
- Scaling Up Instructions (5.1):
- The autoscaler instructs the revision's deployment to scale up to N > 0 replicas to accommodate the increased demand.
- Serve Mode Activation (5.2):
- The autoscaler switches the SKS into Serve mode, directing traffic to the revision's pods directly once they are up.
- Endpoint Probing:
- The activator monitors the SKS's private service for the appearance of endpoints.
- Once the endpoints come up and pass the probe successfully, the respective address is considered healthy and used to route the buffered request and any additional requests that arrived in the meantime (8.2).
- Successful Scaling Up:
- The revision has successfully scaled up from zero to handle the incoming request.
Conclusion
In summary, we've explored the core concepts of Knative Serving, from its architecture to scaling mechanisms. Next, we'll dive into practical implementation in our upcoming blog. Also, stay tuned for the integration of the serverless component into the WeDAA Platform, making prototyping and deployment faster and easier than ever.